- A+
所属分类:百科知识
大家在写论文时可能经常会遇到大数据样本中异常数据批量剔除的问题,本文在于向大家推荐在Stata中运用winsorize方法,来对数据进行处理(缩尾使数据平滑,或直接删除),经试验有效,希望有所帮助。
Stata(网上有面安装款,解压能直接运行),实验数据
打开stata,在命令行输入ssc install winsor2, replace,自动安装 winsor2
-1")
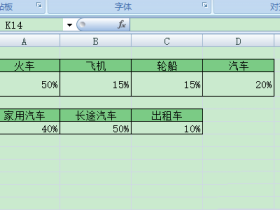
准备数据(注意输入格式)
-2")
导入数据File-Inport
-3")
输入命令winsor2 变量名 变量名, replace cuts(1 99),此条命令是先找到各个变量的1%,99%所对应的分位数,比如对于变量ac1,其分位数分别为a、b,那么将数据中小于a的数替换成a,将大于b的数替换成b,原始数据直接变为新数据,这样就是缩尾,使数据平滑(口径为1%)。若输入命令winsor2 变量名 变量名, replace cuts(1 99) trim,则不替换,将小于a和大于b的直接删除
-4")
最后一张图显示的是命令winsor2 ac1 ac2, replace cuts(1 99) trim命令的执行结果,大家看到数据表中的“.”,即是删除完异常值后的结果,批量处理后可以File-Export将数据导出,在Excel上排序后即可将其删除(或在STATA上用其他命令也可)
-5")